
Dojo chip is designed to attain scalable computers which can be added as many cores as possible, achieve low latency, and fast chip-to-chip communication. The D1 chip is designed to execute large compute plates with extremely high bandwidth.
The architecture of the Dojo computer:
D1 chip is a distributed computer where all the training nodes are basically computed elements that are connected with any kind of network which is two-dimensional.

D1 chip:
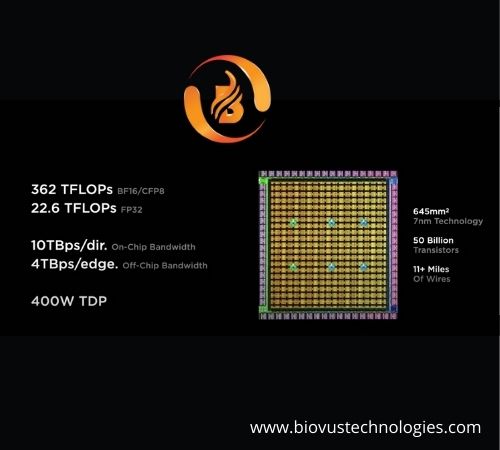
A D1 chip is fabricated with 7nm technology which is 645 mm square in size, with 50 billion transistors capable of processing 362 Tflops in BF16 / CFP8 power. It has 354 training nodes that compose its functional unit and are coupled to form a large chip. Each training node is equipped with a quad-core, 64-bit ISA CPU that performs transpositions, compilations, broadcasts, and link traversal using a customized, bespoke architecture. This CPU makes use of a superscalar implementation (4-wide scalar and 2-wide vector pipelines).
On the unit network, each functional unit has 1.25 MB SRAM and 512 GB/sec bandwidth in any direction. The CPUs are linked in multichip combinations of 25 D1 units, dubbed “Dojo Interface Processors” by Tesla (DIPs).
D1 chip training tail:
The training node’s design consists of four wide scalar and two wide vector pipes, as well as four-way multithreading. When we compute 354 training nodes, we get 362 Tflops since the computing array is coupled to a high-bandwidth network and encircled by 576 lanes of high-speed, low-power servers.

On fan-out wafer technology, 25 D1 chips are diced and firmly integrated with each other. A high-bandwidth, high-density connection is also included within the tile. In addition, a voltage regulator module is placed directly on the plane of the fan-out wafer technology. The electrical, thermal, and mechanical components are all merged to make a fully integrated training tile with a 52-volt dc input.
Visit us at: www.biovustechnologies.com





